HIS 2021 Casablanca/Atelier Wicri/Article version 1

Cette page introduit un projet d'article pour le colloque HIS.7.
- Projet de titre
- Bibliothèques hypertextes pour la gestion et la valorisation du patrimoine
- Sous-titre
- Une application pilote avec la Chanson de Roland
Sommaire
- 1 Introduction
- 2 Des bibliothèques de manuscrits aux bibliothèques hypertextes
- 3 La genèse du projet Wicri/Chanson de Roland
- 4 La Chanson de Roland, expérience pilote dans les humanités numériques
- 5 Le chantier de la Chanson de Roland
- 6 Analyses et perspectives
- 7 Les racines du projet Wicri
- 8 Applications aux humanités et patrimoines numériques
- 9 Conclusion
- 10 Notes
- 11 Bibliographie
- Avant-propos
Cet article est rédigé sur le wiki Wicri/Chanson de Roland. Les travaux sur le wiki sont réalisés en relation avec sa rédaction.
Introduction
- Qu'est-ce qu'une bibliothèque numérique, au juste ?
Il y a 15 ans, Carl Lagoze, un des pionniers des archives ouvertes aux États-Unis posait cette question dans un article de référence [Lagoze 2005]. Le mot hypertexte était absent de cet article.
Au même moment, Wikipédia bouleversait le monde de la connaissance en réalisant une partie des rêves de Paul Otlet. Le réseau Wicri (Wikis pour les communautés de la recherche et de l'innovation) s'est alors appuyé sur cette approche pour proposer un réseau de sites encyclopédiques pour la recherche. Puis, des articles, des livres, y ont été réédités en mode hypertexte. Un site ressemble alors à une bibliothèque où les rayonnages sont remplacés par un substrat encyclopédique.
En 2021, la valorisation simultanée d'un ouvrage annoté par Paul Meyer et celle d'une suite musicale autour de la Chanson de Roland amène à approfondir cette réflexion, dans sa dimension technologique mais aussi historique. En effet, cette chanson de geste fait plonger dans le monde des bibliothèques du Moyen-Âge, avant l'imprimerie. Or les manuscrits deviennent librement accessibles sur le web. Ils ont fait l'objet de nombreux livres de références au XIXe siècle, avant la généralisation des reproductions photographiques. Ces ouvrages, avec des points de vue souvent contradictoires, sont maintenant largement disponibles sur le Web. Des milliers d'articles contemporains explorent cet ensemble dans toutes les directions. Les chercheurs, les bibliothécaires ou les curieux ont besoin de manipuler, de comparer ces fragments et les autres textes qui en discutent. Comment rééditer ces écrits dans un ensemble hypertexte unifié pour favoriser tout type d'exploration.
Ces expériences nous amènent en fait à reposer la question :
- Qu'est-ce qu'une bibliothèque numérique pour le patrimoine au juste ?
Dans cet article, nous donnerons quelques réflexions sur l'évolution des bibliothèques numériques dans une dimension hypertexte. Nous présenterons différents volets de l'expérimentation Wicri dans les humanités numériques avec des exemples sur la Chanson de Roland. Nous présenterons ensuite les aspects originaux liés à cette œuvre. Enfin, nous discuterons de la généralisation des résultats vers d'autres domaines notamment pour la préservation du patrimoine.
Des bibliothèques de manuscrits aux bibliothèques hypertextes
Qu'est-ce qu'une bibliothèque ? Pour le dictionnaire TLF (Trésor de la langue française) c'est : « un lieu où est rangé une collection de livres ». Dans un premier temps nous allons donc approfondir la notion de livre numérique. Mais auparavant, nous donnerons quelques points de repères que la Chanson de Roland.
Quelques repères sur la Chanson de Roland
Le 15 aout 778, de retour d'Espagne, Charlemagne perd son arrière garde, dont Roland, préfet de la Marche de Bretagne, dans la bataille de Roncevaux. Dans une floraison de chansons et d'épopées à la gloire de l'empereur nait la légende de Roland (avec par exemple la traitrise de Ganelon, le son du cor, ou l'épée Durandal qui brise le rocher). Cette épopée est transcrite en manuscrits, objets de multiples copies (et adaptations), dont l'une datée du XIIe siècle est conservé dans un bon état à la bibliothèque Bodléienne à Oxford.
Elle sera cependant oubliée pendant plusieurs siècles. La légende donnera lieu à d'autres poèmes épiques comme par exemple l'Orlando furioso de l'Arioste qui donnera lieu à de multiples compositions musicales ; mais avec un récit assez éloigné du poème initial.
En 1835, Francisque Michel identifie à Oxford le plus ancien manuscrit sur la Chanson de Roland. Il s'en suit une très vive activité de transcriptions et de traductions (en France Léon Gautier, Paul Meyer...), avec des confrontations avec d'autres manuscrits.
Cette activité se poursuit au poursuit au XXe siècle avec de nouvelles traductions (Joseph Bédier...), de multiples adaptations et des publications scientifiques. Sur Google Scolar la requête « Chanson de Roland » sélectionne 30.000 références.
Du papyrus à l'hypertexte en passant par le codex imprimé
Il y a environ 2200 ans, après 300 ans de rédaction en mode page (tablette d'argile, papyrus), le codex est apparue sous la forme d'un assemblage de feuillets (parchemins), où l'on peut tourner les pages et feuilleter. Le livre actuel sous sa version papier ou numérique simple (du fichier Word au PDF) conserve le même type d'organisation.
En 1985, avec les formats SGML puis XML 10 ans plus tard, les documents numériques se structurent en arborescences. Mais cette transformation, fondamentale pour les programmes, est peu visible pour les utilisateurs.
Dans le projet Wicri[1], le passage au numérique utilise la technologie wiki où la notion de page wiki est un peu particulière. En effet, une telle page peut être réduite à quelques caractères (une redirection) ou contenir le contenu intégral d'un ouvrage. Pour de nombreux ouvrages ou articles cette structure en codex a été légèrement aménagée avec un regroupement des pages en chapitres, implantées en pages wiki.
Pour la Chanson de Roland, le manuscrit d'Oxford est une copie d'autres manuscrits qui sont généralement des codex. Ici la structure est un peu particulière : une simple suite de couplets, sans paragraphage, sans numérotation (au départ), sans table des matières. Il aurait pu avantageusement être rédigé dans un volumen (en rouleau). Nous verrons plus loin que son passage en numérique a induit une profonde transformation en hypertexte. D'autres manuscrits devront être traités de façon analogue.
Un premier ensemble d'ouvrages de référence fondamentaux (Francisque Michel, Léon Gautier, Paul Meyer, Stengel) ont été écrits au XIXe siècle. Leur composition est très liée aux contraintes matérielles. Par exemple, la version critique de Paul Gautier est répartie sur 2 tomes. Le premier décline une transcription et une traduction avec un alignement sur les versets (laisses) du manuscrits. Le deuxième tome contient des notes qui pointent vers des numéros de vers. Leur passage en numérique demande également une profonde réorganisation dans un ensemble hypertexte.
Les dictionnaires sont également des documents dont la numérisation est particulière. Le cas du TLF est intéressant. Dans le projet initial de Paul Imbs, le dictionnaire a été conçu en 1960 avec un traitement informatique pour produire une collection papier. Dans les années 90, Jacques Dendien a repris les fichiers de compositions pour produire un ouvrage numérique, au départ géré un CD-ROM puis sur un site Web, le TLFi. Le livre est devenu un site Web. Dans l'expérimentation Wicri, des extractions sont réalisées à partir du TLFi pour produire des pages wikis (ou des rubriques de pages wikis). Le TLF devient un hypertexte au milieu d'autres hypertextes.
Dans ce contexte, que devient la bibliothèque ?
La bibliothèque : rayonnages, entrepôt numérique, hypertexte
Pour le TLFi, la définition, élaborée en 1980, d'une bibliothèque est un lieu où l'on range des livres.
Avant le numérique, pour que l'on puisse ranger et retrouver des ouvrages des dispositifs d'accompagnement ont été développés, plans de classements, fichiers matière, fichiers auteurs etc.
En fait, dans un premier temps, jusqu'en 1990, l'automatisation des bibliothèques a consisté à informatiser les métadonnées de classement pour permettre à un OPAC de fournir un titre et une côte. Et puis, les documents ont été numérisés, avec un OCR souvent sommaire, mais qui permettait d'améliorer le moteur de recherche d'une bibliothèque. La plupart des entrepôts de données de type archives ouvertes fonctionnent dans ce paradigme.
L'article de Carl Lagoze arrive dans un contexte où l'on sait de mieux en mieux fédérer des réseaux de bibliothèques numériques par du moissonnage ou des requêtes simultanées avec des formats comme le Dublin Core. L'utilisateur ne sait plus quelle bibliothèque a répondu à sa requête. Ce phénomène est accentué avec l'irruption des triplets RDF. Mais le résultat d'une requête est généralement un document.
Quand les documents sont des hypertextes, il n'y a plus de frontière bien définie entre une bibliothèque numérique et ses documents. Un moteur de recherche délivre des fragments...
Le moteur MediaWiki est particulièrement concerné par ce phénomène. Le même logiciel peut gérer un immense document (Wikipédia), un entrepôts d'objets multimedia structuré par des articles (Wikimedia Commons), une bibliothèque de document en textes intégral (WikiSource), etc.
L'ensemble des sites du projet Wicri est souvent présenté comme un réseau de bibliothèques numériques où cohabitent des parties encyclopédiques et des documents. Ces parties encyclopédique jouent en partie le même rôle que les fichiers matières dans une bibliothèque classique. L'image d'une bibliothèque où la couche encyclopédique remplace les rayonnages a donc été utilisée.
Dans le cas de la Chanson de Roland, l'ensemble des manuscrits et des ouvrages qui leur sont directement associés deviennent des hypertextes. La frontière entre la bibliothèque et les documents explose. Nous parlerons de bibliothèque hypertexte.
La bibliothèque : salle de lecture, scriptorium, learning center
De tout temps, la bibliothèque a été une salle de lecture. Cette fonction est devenue de plus en plus virtuelle avec l'extension du numérique, ou les chercheurs explorent les bibliothèques numériques.
Du temps des manuscrits, notamment dans les monastères, le scriptorium était un atelier où travaillaient les copistes, généralement sous la conduite d'un bibliothécaire. L'imprimerie a déporté cette fonction chez les imprimeurs.
Avec des CMS traditionnels (type HAL), la bibliothèque est un lieu de dépôt où le temps de travail est relativement limité. Avec les CMS à haut degré de paramétrage et d'interaction (exemple les modèles de MediaWiki), la bibliothèque numérique redevient un espace de travail collectif.
Sur Wikipédia, la communauté des contributeurs joue un rôle d'apprentisssage proche de celui des leranins centers des bibliothèques universitaires.
La genèse du projet Wicri/Chanson de Roland
L'expérience sur la Chanson de Roland est issue d'un concours de circonstances qui mérite d'être rapporté car il illustre la réactivité des approches étudiées dans ce projet. Voici donc les points de départ de cette aventure.
En 2008, l'expérience Wikipédia montrait que des milliers de volontaires pouvaient trouver du plaisir à construire un immense service de diffusion de connaissances. Le réseau Wicri a été créé pour tester cette approche sur un ensemble de bibliothèques thématiques ou régionales dédiées à la valorisation des recherches en cours. Des expérimentations ont été également menées en sciences humaines. Elles ont conduit à expérimenter des rééditions numériques, par exemple sur l'histoire de la Lorraine ou en musique .
Francisque Michel annoté par Paul Meyer
En 2011, suite au bon accueil d'une réédition d'un ouvrage d'Henri Lepage édité en 1852 sur le Palais Ducal de Nancy, l'équipe Wicri a été sollicitée pour assister un stagiaire en philologie.

En effet, la Bibliothèque universitaire de Lettres de Nancy (BUL) est dépositaire d'un fonds Paul Meyer dont l'un des objet de référence est « La Chanson de Roland et le Roman de Roncevaux des XIIe et XIIIe siècles » écrit par Francisque Michel et annoté par Paul Meyer. Cet ouvrage s'appuie sur un manuscrit possédé par la bibliothèque Bodléienne à Oxford. L'équipe Wicri a donc apporté un soutien logistique pour rééditer cet ouvrage sur un wiki dédiée aux collections de la BUL en 2014.
D'Irish Mass à la Chanson de Roland
De façon totalement indépendante, sur un wiki dédié à la musique, en 2018, l'équipe Wicri a procédé à une mise en ligne des partitions d'une œuvre du compositeur Gilles Mathieu. Cette pièce, nommée Irish Mass (messe irlandaise), avait fait l'objet d'une œuvre régionale pour les chorales de la fédération A Cœur Joie Lorraine. Le site avait été construit pour permettre aux choristes de trouver des outils d'apprentissage et surtout, pour les chanteurs ou auditeurs curieux, de découvrir le contexte culturel et musical de l’œuvre.
Or Gilles Mathieu a aussi réalisé une suite sur la Chanson de Roland (qui avait été interprétée par la Chorale Universitaire de Nancy).
Un stage déclencheur
En 2021, le projet Wicri a été sollicité pour accueillir des stages d’étudiants en L3 sciences cognitives. Un des candidats avait une bonne culture musicale. Une mission de stage a été définie, en mai 2021, pour étudier le rapprochement numérique de la réédition de Francisque Michel avec une transcription de la suite musicale de Gilles Mathieu. L'idée était de s'appuyer sur le manuscrit d'Oxford (facilement accessible sur Wikimedia Commons) comme média intermédiaire.
Le problème s'est révélé beaucoup plus complexe et plus intéressant qu'il n'avait été imaginé. En effet, Gilles Mathieu, s'est appuyé sur une autre transcription du manuscrit, réalisée par Paul Gautier. Or Francisque Michel a des divergences d'interprétation. Par exemple, ces deux philologues ne sont pas d'accord sur le découpage du texte du manuscrit en couplets.
A ce point, il est utilise de préciser que ce sujet a été abordé avec des acteurs qui n'avaient aucune connaissance du monde des chansons de geste. Nous avons cependant réalisé très rapidement l'ampleur le sujet et son intérêt. Il a donc été décidé de mener une étude de faisabilité d'un projet de grande ampleur autour des multiples sources et travaux sur la Chanson de Roland.
La Chanson de Roland, expérience pilote dans les humanités numériques
En mai 2021, la Chanson de Roland est donc devenue une expérience pilote, avec la création d'un wiki dédié à ce sujet.
Cette section présente différents du projet Wicri qui seront repris par cette expérimentation. Une première section introduit les fonctions qualifiées d'encyclopédique. Une deuxième abordera différentes facettes des rééditions.
La base encyclopédique
De façon générale la première couche encyclopédique de Wicri est une fédération d'observatoires sur les recherches en cours. Les travaux sur (ou autour de) la Chanson de Roland sont abondants (par exemple, 30.000 documents sur Google Scolar). Face à l'abondance de cette littérature, le wiki Wicri/Chanson de Roland devra intégrer un observatoire qui est encore embryonnaire.
Sur chaque wiki, ce noyau est ensuite complété par des données propres au domaine (par exemple, la classification du vivant dans les domaines de l'environnement). Cet ensemble forme la base encyclopédique. L'expérimentation sur la Chanson de Roland permet d'approfondir cette réflexion dans le champ des applications du patrimoine. L'objectif actuel du projet est de l'explorer de façon transversale (sans chercher à l'exhaustivité dans les branches).
Première étape : signalements et mises en fiches
La couche encyclopédique joue un premier rôle de glossaire alimenté de façon pragmatique (en fonction de l'intérêt des sujets) et non par ordre alphabétique.
Le mode d'alimentation est proche de celui de Wikipédia, où le nommage des objets ou concepts joue un rôle fondamental. MediaWiki, offre une palette de dispositifs, pour faciliter ce travail, et notamment les redirections et outils de gestion des pages. Citons également les pages de discussions ou les pages personnelles, où l'on peut déjà noter des informations brutes ou des questionnements. Pour faciliter la tâche des contributeurs, (et l'insertion dans le Web sémantique) le nommage de ces pages est, si possible, aligné sur Wikipédia.
Une fois les objets identifiés, un autre point fort de MediaWiki est la puissance des modèles qui donnent aux spécialistes d'un domaine une très grande autonomie de développements. Par exemple, sur Wikipédia, chaque communauté peut définir ses propres boîtes de description (infobox) pour décrire ces objets.
Le signalement des recherches en cours est basé sur les publications avec des métadonnées relativement classiques. L'identification des grandes revues (exemple Romania) ou des grands colloques (exemple : Rencesvals) est un premier point d'entrée pour localiser (et mettre en fiches) les personnalités essentielles (via les comités) les articles fondamentaux, les institutions dans leurs contextes géographiques actuels.
Avec l'introduction des indicateurs dans le vie académique depuis 30 ans, l'identification de ces éléments est relativement facile. Les acteurs et les organismes vont être répartis sur des pages wikis avec les liens vers d'autres pages affectés aux entités géographiques.
Au delà des recherches en cours plusieurs types de données doivent être pris en compte par exemple la littérature historique, et le sujet proprement dit.
Les éléments de la littérature historique (des manuscrits aux ouvrages des années 1950 en passant par les traductions du XIXe siècle) sont apparues plus complexes à identifier. Il faut par exemple intégrer les multiples variantes historiques des éléments bibliographiques (en s'appuyant notamment sur Data.bnf).
L'histoire de la Chanson de Roland, avec ses personnages, ses lieux, ses évènements ouvre un autre champ d'investigation où il faut expliciter ce qui relève de l'histoire où de la légende. Il faut également intégrer les autres récits (chansons de geste...) qui l'ont inspiré.
La Chanson de Roland est également une source de textes de références pour les études sur les langues médiévales.
Enfin, la Chanson de Roland a inspiré une multitude d’œuvres romanesques, théâtrales, musicales ou cinématographiques dans différentes régions pour différents publics.
La base encyclopédique est donc potentiellement très riche.
Réseaux sémantiques dans la base encyclopédique
Tous ces éléments doivent faire l'objet de fiches commentées en reliées dans la base encyclopédique.
MediaWiki propose un mécanisme de catégories hiérarchisées. Il permet de définir un thésaurus qui apporte un premier élément de structuration sémantique.
Le réseau Wicri utilise également les extensions sémantiques (Semantic MediaWiki). Elles permettent d'affecter un nom de propriété aux liens entre pages. Par exemple, dans la page décrivant le colloque Rencesvals 2020 Nancy, la mention de l'Université de Lorraine en tant qu'organisatrice est codifiée ainsi :
[[A pour organisateur::Université de Lorraine]]Sur la page de l'Université, un modèle nommé {{Wicri voir aussi, université}} permet alors d'afficher automatiquement la liste des manifestations organisées par cette institution.
Ce modèle sémantique des organisations a été rodé dans des domaines où les chercheurs sont attentifs au signalement de leurs affiliations, où les organisations de colloques sont formalisées et où les pratiques liées à la science ouverte se généralisent. Ici, cette formalisation est plus complexe. Par exemple, dans les congrès de la Société Rencesvals, la notion de comité de programme est nettement plus floue, avec un comité d'organisation qui joue manifestement un rôle de sélection scientifique.
Chaque type de travail peut apporter ses propres relations sémantiques. Un étude sur les variantes orthographiques avait été réalisée autour de la réédition de l'ouvrage de Francisque Michel avec l'introduction d'attributs comme « A pour variante de Charlemagne ». Le travail sur les manuscrits décrit plus loin demande l'introduction de nouveaux attributs comme « A pour orateur ».
Pour les lecteurs, la navigation élémentaire est transparente (comme sur Wikipédia). Une formation légère permet de bénéficier d'une navigation experte. Pour les contributeurs, une petite formation est nécessaire pour utiliser une ontologie existante. L'adjonction de nouveaux attributs relève de la conception d'ontologies.
Les serveurs d'explorations pour enrichir la base encyclopédique
Pour enrichir de façon prospective la couche encyclopédique, le projet Wicri utilise des techniques d'explorations de corpus de publications.
Cette expérience est ancienne. En effet, dans les années 90, un projet nommé ILIB a été développé à l'INIST pour améliorer l'exploitation des bases Pascal et Francis en utilisant SGML pour les métadonnées bibliographiques[2]. Un peu plus tard, au LORIA, une nouvelle version nommée DILIB, permettait d'assembler des modules en interface XMl pour générer des systèmes de recherche d'information incluant des fonctions infométriques (notamment des algorithmes de classification).
Dans les années 2000, les services proposés reposaient sur des corpus de métadonnées hétérogènes (exemple Pascal et Medline) mais bien structurés. Les résultats étaient généralement livrés sous forme de rapport accompagnés d'une extraction de quelques références bibliographiques pertinentes (par exemple 200 sur un ensemble de 5000 notices initiales).
Grâce au programme ISTEX, nous avons repris ce type d'expérimentation (150 sur quelques années). Une grande partie a été réalisée dans le cadre de travaux dirigés dans des master en science de l'information. Par rapport à la phase précédente l’infrastructure wiki a apporté des améliorations notables :
- Il est maintenant possible de traiter des documents en texte intégral (normalisation TEI notamment).
- Les rapports deviennent des pages wikis sur lesquelles on trouve notamment des projection géographiques.
- les corpus sont extérieurs au wiki mais sont visibles dans leur intégralité. Il est donc possible d'analyser la qualité statistique du corpus (en allant, par exemple, explorer des régions de faible occurrence)
- La génération des serveurs est réalisée à partir d'un paramétrage réalisé dans les pages du wiki (au lieu d'un assemblage assez complexe dans des scripts en shell d'unix).
- Des règles de curation peuvent être exprimées dans le wiki en s'appuyant sur la formalisation sémantique contenue dans le wiki.
Cohérence sémantique dans le réseau
Cette couche encyclopédique est en grande partie indépendant d'un domaine donné. Le réseau de wikis apporte alors une aide importante pour bâtir les fondations d'un nouveau wiki.
Le réseau actuel est un ensemble d'une vingtaine de familles multilingues à couverture géographique, un autre ensemble équivalent de sites scientifiques, quelques wikis spécialisés, et des wikis techniques. Un des wikis techniques (Wicri/Base) contient un ensemble d'un millier de modèles et métadonnées communes qui apporte un premier niveau de cohérence sémantique au réseau.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Rééditions numériques hypertextuelles
Les rééditions structurantes, puis éditoriales
Pour construire un observatoire des recherches dans un champ donné, la réalisation d'un ensemble sémantique de fiches relatives aux chercheurs, laboratoires, congrès, publications, entités géographiques est « relativement simple » et quantifiable. La fusion de 4 universités demande de nombreuses modifications dans le réseau mais qui restent facilement programmables.
En revanche la rédaction d'une page de synthèse sur « la recherche en Lorraine » sur Wicri, ou la tentative de reconstruire une page correcte sur le concept de métadonnées sur Wikipédia s'avèrent complexe et demande un travail de rédaction très conséquent.
Dans le réseau Wicri, les premières rééditions ont été motivées par le besoin d'offrir rapidement des textes de synthèse. Ainsi le premier exemple a été : le CPER (Contrat de plan état région) de la Région Lorraine en 2007. Le document a été en fait réédité pour permettre une meilleure lisibilité en ligne et l'insertion de liens et d'annotations sémantiques.
A l'occasion d'une action politique nancéienne sur la Renaissance, un premier test de réédition dans une perspective hypertexte a été réalisée sur un ouvrage écrit par Henri Lepage en 1852 sur le Palais Ducal de Nancy. Les opérations suivantes ont été réalisées :
- mise en ligne sous la forme d'un ensemble de pages wikis avec des mécanismes de navigation entre les chapitres,
- correction de l'OCR issu de Gallica, (ce texte devient réutilisable)
- insertion de nombreux liens sémantiques avec enrichissement du wiki sur l'histoire de la Lorraine (aspects structurants du domaine sur le wiki qui joue un rôle de glossaire)
- reprise d'une figure contenant de nombreuses ancres (sous la forme de lettres majuscules) par une carte cliquable.
Dans cet exemple, il s'agit bien d'une réédition d'un ouvrage et pas simplement d'un archivage. De son coté le wiki n'est plus simplement un ensemble de pages ou de fiches mais commence à ressembler à une bibliothèque.
Valorisation des publications
Pour les sciences de l'information, le projet Wicri implémente un réseau de bibliothèques, avec deux niveaux de validation. Trois wikis sont affectés à des communautés scientifiques (CIDE, H2PTM, VSST). Tous les articles acceptés peuvent donc y être transcrits, indexés, annotés, commentés dans les pages de discussion. Dans le contexte ISTEX, des étudiants (sous encadrement avancé) ont réalisé des serveurs d'exploration qui permettent d'éclairer la couverture de la communauté de ces colloques avec la production internationale. Sur cet ensemble, un wiki thématique commun (Wicri/Sciences de l'Information) va mettre en valeur les meilleurs articles.
Ces articles sont généralement transcrits en wikitexte pour bénéficier des mécanismes d'indexation sémantique (et être analysés par le moteur de recherche du wiki).
Concernant la Chanson de Roland, cette phase en en cours de démarrage. Elle pose quelques problèmes spécifiques :
- Les pratiques liées à la science ouverte sont encore peu répandues dans la communauté scientifique concernée. Il est donc difficile de valoriser des articles récents.
- La lecture de nombreux articles demande une solide érudition. Le wiki doit donc offrir une collection d'articles abordables par un plus large public.
- Ces articles font des références aux manuscrits originaux et à leurs transcriptions et traductions historiques.
Ce dernier point fait l'objet des travaux prioritaires et sera détaillé dans la section suivante.
La musique
Le wiki Wicri/Musique introduit une dimension multimédia qui offre un volet très démonstratif dans la valorisation du patrimoine écrit. Dans une bibliothèque classique ou sur Gallica la lecture avancée d'un livre traitant de musique implique que le lecteur soit capable d'interpréter une partition. Sur Wikipédia ou dans le réseau Wicri la musique peut être immédiatement écoutée[3].
La technologie utilisée repose sur le logiciel de gravure musicale LilyPond. La musique y est codée dans un langage formel dont la syntaxe rappelle celle de TeX pour les mathématiques. Voici par exemple les premières notes d'au clair de la lune en si bémol majeur :
|
\relative c' {
\time 4/4
\key bes \major
bes4 bes4 bes4 c4
d2 c2 }
|
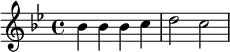 |
Les musiciens sont souvent partagés sur les avantages de cette pratique par rapport aux systèmes WYSIWIG, notamment pour les compositions conséquentes. Ici, de nombreux articles contiennent beaucoup de texte avec de courtes séquences musicales sur lesquelles plusieurs contributeurs peuvent intervenir.
Cette approche est mise en œuvre pour rééditer des articles issus notamment de Gallica. Des articles originaux ont été produits avec comme objectif éditoriaux d'aider les choristes interprétant des pièces de la Renaissance à comprendre les mécanismes de transcription à partir des partitions originales. Une pièce contemporaine (Irish Mass de Gilles Mathieu) a été rééditée sur une cinquantaine de pages wikis (soit des centaines de pages effectives), pour offrir des outils de travail à destination des choristes et des articles pour l'approfondissement du contexte et de la musique.
Les dictionnaires
L'article carillon du Dictionnaire de musique de Jean-Jacques Rousseau (1767) a été l'un des premiers articles de réédition avec une partition sur Wicri/Musique.
Sur Wicri/Musique, à partir de ce premier essai, des travaux ont été menés pour permettre des comparaisons entre plusieurs dictionnaires :
- Le dictionnaire de Jean-Jacques Rousseau ;
- Le dictionnaire de musique de Sébastien de Brossard (1703) ;
- l'Encyclopédie de Diderot en 1751 (dans laquelle Diderot a rédigé les articles de musique)
- le Trésor de la Langue Française (1970 - 1990)
Les dictionnaires sont en fait « découpés en articles » pour que les définitions puissent être comparées.
Pour la TLF il est alors possible de rétablir des liens entre les entrées et les textes de référence. Ainsi sur Wicri/Santé l'introduction à la médecine expérimentale de Claude Bernard est rééditées car elle est très souvent citée dans le TLF pour les articles médicaux. Cet exemple montre la faisabilité d'un ensemble constitué d'un dictionnaire de langue en construction incrémentale avec un ensemble de textes réédités dans cette bibliothèque.
Pour la Chanson de Roland, le TLF utilise ce texte, notamment dans la transcription de Bédier, pour donner des attestations (exemple définition de mule).
Le chantier de la Chanson de Roland
Par rapport aux expérimentations déjà engagées, celle sur la Chanson de Roland montre un autre type d'utilisation de ce modèle de bibliothèque encyclopédique.
En effet cette chanson de geste a généré un nombre considérable de livres, articles ou objets multimédia. Basés à l'origine sur une tradition orale elle a donné lieu à de multiples variantes. Par un concours de circonstances nous avons été amené à contruire un ensemble numérique où les principaux acteurs n'avaient au départ aucune connaissance de cette chanson de geste autre que de vieux souvenirs scolaires (pour les plus anciens !). La construction de cette bibliothèque numérique est donc une expérimentation très significative d'une construction itérative d'un système information scientifique.
Les sources et la modélisation de leur réseau
A partir d'une une histoire du VIIIe siècle, la Chanson de Roland rassemble un large panorama d'informations patrimoniales hétérogènes : , des manuscrits du XIIe siècle, des ouvrages du XIXe siècle, de multiples publications au XXe siècle et une composition musicale du XXIe siècle. Toutes ces sources peuvent être rééditées, découpées, ré-assemblées dans une formulation hypertexte.
Grandes difficultés de trouver les informations (avalanche de sources, hétérogénéité; hermétisme sans érudition).
Dans un premier temps, une priorité s'est manifestée : la gestion des sources primaires (manuscrits), leurs transcriptions et leurs traduction. En effet, la plupart des articles contiennent des références sous la forme de numéro de vers ou de numéro de laisse.
L'organisation des manuscrits parait relativement simple. Un manuscrit est un ensemble de vers qui sont d'une part répartis sur un ensemble de feuillets recto verso, et d'autre part regroupés en couplets (laisses). Une laisse contient des vers rimés et commence par une lettrine. Elle peut être à cheval sur 2 pages.
En fait, dès que l'on cherche à aligner plusieurs ouvrages primaires (transcription) avec un manuscrit les divergences de numérotation sont omniprésentes. Ainsi la dernière laisse est numérotée CCXCI chez Roland Bédier, CCXCIII chez Edmund Stengel, CCXCVI chez Francisque Michel et CCXCVII chez Léon Gautier.
Premier essai d'association entre le l'ouvrage de Francisque Michel et les le manuscrit d'Oxford.
Les manuscrits
- feuillets
- laisses
- vers
- erreurs des copistes
Les transcriptions, les traductions
Les études
Les interactions entre un Oratorio profane, les manuscrits et les traductions
Blog dialogue avec un compositeur
Analyses et perspectives
Les approches et technologies ici expérimentées sont largement utilisées au niveau mondial dans des applications souvent spécialisées. Le projet Wicri veut offrir, sur un sujet donné, ici la Chanson de Roland, une infrastructure commune pour multiples applications.
Transmission des connaissances
Autonomie des acteurs du patrimoine
Grands projets ?
Les racines du projet Wicri
Cette section repose sur des informations détaillées sur le wiki Wicri/Histoire de l'IST sur lequel des témoignages basés sur la mémoire sont confrontés à des documents des années 1970 - 2000. Ils sont remis en perspective avec des ouvrages plus anciens (Paul Otlet) et des études historiques pouvant à l'antiquité.
En réalité ce projet a été créé en Lorraine par des acteurs impliqués il y a 50 ans d'abord dans le développement de l'informatique au service de la recherche, puis dans de grandes réalisations de la connaissance numérique au service de la société : le Dictionnaire Trésor de la Langue Française (TLF) et les bases Pascal et Francis.
L'informatique s'est développée au CNRS dans le département « sciences pour l'ingénieur (SPI) ». Le CNRS voulait accompagner les ingénieurs afin qu'ils puissent résoudre collectivement des problèmes de grande complexité.
En 2020, la résolution des applications complexes dans les humanités exige également une appropriation conséquente du numérique.
- Le projet Wicri explore maintenant les outils et pratiques qui peuvent être appropriées par les chercheurs et praticiens du patrimoine culturel.
Dans les années 65 à 95, le TLF a mobilisé près d'une centaine de linguistes de haut niveau pour produire un dictionnaire de référence. En 90 - 95 Le TLFi (TLF informatisé en ligne) a offert une transposition numérique de ce document.
De 1945 à 1992, des centaines d'ingénieurs de haut niveau ont édités les bulletins signalétiques du CNRS. Ils rédigeaient des résumés en français accompagnée d'une indexation contrôlée pour offrir à la société une synthèse périodique et analysée de l'essentiel de la production scientifique mondiale. Dans les années 75, le contenu des bulletins a été automatisé pour produire les bases Pascal et Francis. Dans les sciences humaines et la valorisation du patrimoine (BHA) la base Francis était le résultat d'un très large réseau de coopérations.
Dans les années 95, pour des des raisons financières, le CNRS a décidé d'arrêter les travaux sur le dictionnaire TLF et de restreindre les bases Pascal et Francis à la fourniture de documents [4]. En fait, la complexité des chaines de production a joué un rôle important dans la prise de décision du CNRS.
Or quelques années plus tard, dans les années 2000 à 2010, des dizaines de milliers de volontaires ont trouvé du plaisir à construire Wikipédia. Les mécanismes de production de la connaissance numérique ont été bouleversés. Cette dynamique pourrait-elle s'appliquer dans de grands projets académiques pilotés par des scientifiques ?
- Face au déferlement de fausses informations sur le web, le projet Wicri explore les outils et pratiques qui pourraient relancer de grandes applications d'information scientifique ou culturelle pilotées par les communautés de la recherche
Pour progresser dans ces objectifs, deux ruptures technologiques ont été étudiées d'abord la technologie XML, puis les wikis programmables et sémantiques.
SGML puis XML pour l'exploration des corpus
Créé en 1986 pour des applications industrielles, le standard SGML s'est rapidement diffusé dans les humanités numériques avec les recommandations TEI en 1988.
Par rapport aux objectifs visés plus haut, des améliorations notables ont été apportées. Mais quelques verrous technologiques n'étaient pas résolus. Par exemple :
- Les chaînes de production pour des applications comme le TLF ou Pascal demandaient encore des investissements très conséquents, avec des délais se chiffrant en années entre la décision politique et sa réalisation.
- Du côté des ingénieurs, l'utilisation des outils XML exigeait une maitrise conséquente de la programmation C sous Unix. [5]
- Dans les serveur d'exploration qui seront évoqués plus loin, la gestion des ontologies nécessaires à la curation de données était encore très complexe.
Un réseau d'encyclopédies pour transmettre la connaissance scientifique
Les serveurs d'explorations
Nous avons évoqué plus haut l'assemblage de composants XML pour générer des dispositifs personnalisés d'exploration de corpus.
Rééditions
L'expérimentation Wicri
L'expérimentation « Wicri » est actuellement portée par le laboratoire Paragraphe de l'Université Paris 8. En fait, le réseau Wicri a été créé il y a 10 ans par des acteurs impliqués depuis 50 ans sur le développement de l'informatique pour la recherche (LORIA), et, au CNRS, sur des grands projets de diffusion de la connaissance au service de la société (INIST, TLF). Ces projets rencontraient de très grandes difficultés.
Or, en 2008, l'expérience Wikipédia montrait que des milliers de volontaires pouvaient trouver du plaisir à construire un immense service de diffusion de connaissances. La DRRT Lorraine, en accord avec Nancy Université, a donc soutenu un programme nommé WICRI (Wikis pour les communautés de la recherche et de l'innovation) afin de voir si cette approche pouvait s'appliquer à la construction d'observatoires de la recherche, type CRIS[6], mais avec une forte dimension éditoriale.
Quelques wikis ont été créés avec MediaWiki, le moteur de Wikipédia, mais avec des différences fondamentales.
- Les chercheurs produisent des informations originales et donc non sourcées. L'anonymat est donc exclu et tous les contributeurs sont sélectionnés et identifiables.
- Wikipédia est une gigantesque encyclopédie assemblée dans un seul ouvrage. Wicri est un réseau de sites scientifiques où chacun peut être piloté par une communauté scientifique.
- Des extensions sémantiques ont été ajoutées pour une meilleure modélisation des systèmes de recherche.
Ce réseau a servi de support pour des centaines d'expérimentations, notamment dans les sciences de l'environnement, et récemment, dans la santé dans le cadre des mobilisations sur le COVID.
Des expérimentations ont été également menées en sciences humaines. Elles ont conduit à expérimenter des rééditions numériques, par exemple sur l'histoire de la Lorraine ou en musique .
Applications aux humanités et patrimoines numériques
Nous venons de présenter des aspects universels de l'approche Wicri. Les différentes communautés scientifiques ont des relations différentes avec leurs production scientifique. Par exemple, en informatique, la plus récente publication sur un algorithme donné rend caduque, et pratiquement sans intérêt (hors évaluation) la plupart des précédentes. Dans les sciences du vivant une observation de terrain des années 1920 peut avoir un intérêt en 2020. Sur Wicri/Santé, dans l'espace dédié au Covid, un ouvrage de Gustave André écrit en 1908 sur la pandémie grippale de 1889 retrouve une actualité singulière en 2020.
Le wiki Wicri/Histoire de l'IST
Les wikis cités au paragraphe précédents sont plutôt dédiés à l'actualité des sciences de l'information. Le wiki « histoire de l'IST » s'intéresse à l'information scientifique dans l'histoire.
Un des motifs de la création de ce wiki était de mieux comprendre les raisons de l’effondrement des bases Pascal/Francis et du dictionnaire TLF. Il s'agissait donc de travailler sur 50 ans d'histoire dans une dimension comparative (avec par exemple une comparaison avec la situation aux États-Unis). Or la création des bulletins scientifiques du CNRS en 1945 trouve une antériorité avec les tables annuelles de constantes éditées en 1910, et donc à la même période que les travaux de Paul Otlet.
Il nous a donc paru intéressant de situer cette analyse dans un paysage plus large. La page d'accueil du wiki cite notamment la tablette babylonienne YBC 7289 qui décrit le calcul de et qui est datée entre 1900 et 1600 av. J.-C..

Le wiki intègre donc des rééditions couvrant une large période historique.
Une démarche réalisée pendant un stage illustre la démarche recherchée. La mission portait sur l'histoire de l'IST en francophonie. Un article ancien du BBF a été réédité et attiré l'attention sur les problèmes liés à la santé. Un serveur d'exploration a dons été lancé à partir d'une recherche sur PubMed. Elle a permis de repérer un acteur tunisien important (Ahmed Ben Abdelaziz) dont les articles ont montré le rôle important de l'Institut Pasteur vers 1900. Un travail sur cet époque a permis de repérer le rôle de Ibl Al Jassar à Kairouan au Xe siècle.
Conclusion
Progressivement et paradoxalement, sur un support numérique, nous avons travaillé comme les bibliothécaires, les copistes et... les savants avant l'invention de l'imprimerie. La bibliothèque n'était pas seulement un lieu de stockage de la connaissance mais avant tout un espace de travail et d'échange scientifique.
Notes
- ↑ L'expérimentation « Wicri » (Wikis pour les Communautés de la Recherche et de l'Innovation) est actuellement portée par le laboratoire Paragraphe de l'Université Paris 8. En fait, le réseau Wicri a été créé il y a 10 ans par des acteurs impliqués depuis 50 ans sur le développement de l'informatique pour la recherche (LORIA), et, au CNRS, sur des grands projets de diffusion de la connaissance au service de la société (INIST, TLF).
- ↑ Par exemple Avec les formats précédents (ISO 2709), toute requête exploratoire demandée par un ingénieur documentaliste demandait quelques jours de développement informatique. Avec cette boîte à outils il suffisait sous unix de lancer une requête paramétrée par une préfiguration des Xpath pour résoudre la plupart des demandes.
- ↑ Au moment où cet article est rédigé, pour des raisons de sécurité cette fonction est provisoirement désactivée sur Wikipédia.
- ↑ Pendant la même période la NLM a doublé la production de la base PubMed réalisée par des spécialistes, assistés et non dominés, par les algorithmes.
- ↑ Un programme de formation avait été déployé sur une centaine d'ingénieurs sur plusieurs années. L'étape initiale de « formation Unix - Langage C - analyseurs lexicographique » était souvent très mal vécue. En revanche, les témoignages en fin d'opération étaient plutôt satisfaisants (y compris sur la nécessité de vaincre le blocage initial).
- ↑ Current Reseach Information System
Bibliographie
[Lagoze 2005] ↑
Carl Lagoze, et al. What Is a Digital Library Anymore, Anyway? In: D-Lib Magazine, 11 2005
Traduit dans la revue AMETIST : Qu'est-ce qu'une bibliothèque numérique, au juste ? Juin 2006